 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
Vitalik:通過更多反相關激勵支持去中心化質押

 金色財經
企業專欄
剛剛
金色財經
企業專欄
剛剛
 關注
關注
作者:Vitalik Buterin,@vitalik.eth;編譯:松雪,金色財經
激勵協議中更好的去中心化的一種策略是懲罰相關性。 也就是說,如果一個參與者行爲不當(包括意外),那么與他們同時行爲不當的其他參與者(以總 ETH 衡量)越多,他們受到的懲罰就會越大。 該理論認爲,如果你是一個大型參與者,那么你所犯的任何錯誤都更有可能在你控制的所有“身份”中復制,即使你將你的代幣分散到許多名義上獨立的账戶中。
這項技術已經在以太坊削減(以及可以說是不活動泄漏)機制中得到應用。 然而,僅在極特殊的攻擊情況下出現的邊緣情況激勵措施在實踐中可能永遠不會出現,可能不足以激勵去中心化。
這篇文章建議將類似的反相關激勵擴展到更“平凡”的失敗案例中,例如錯過證明,幾乎所有驗證者至少偶爾都會這樣做。 該理論認爲,較大的質押者,包括富有的個人和質押池,將在同一互聯網連接甚至同一台物理計算機上運行許多驗證器,這將導致不成比例的相關失敗。 這樣的質押者總是可以爲每個節點進行獨立的物理設置,但如果他們最終這樣做,那就意味着我們已經完全消除了質押的規模經濟。
健全性檢查:同一“集群”中不同驗證器的錯誤實際上更有可能相互關聯嗎?
我們可以通過組合兩個數據集來檢查這一點:(i) 最近一些時期的證明數據,顯示在每個時隙期間哪些驗證器應該經過證明,以及哪些驗證器實際進行了證明,以及 (ii) 將驗證器 ID 映射到公开的數據包含許多驗證器的集群(例如“Lido”、“Coinbase”、“Vitalik Buterin”)。 您可以在此處、此處和此處 找到前者的轉儲,在此處 找到後者的轉儲。
然後,我們運行一個腳本來計算共同失敗的總數:同一集群中的兩個驗證器的實例被分配在同一時間槽內進行證明,並在該時間槽中失敗。
我們還計算預期的共同故障:如果故障完全是隨機機會的結果,則“應該發生”的共同故障的數量。
例如,假設有 10 個驗證器,其中一個集群大小爲 4,其他集群獨立,並且 3 個驗證器失敗:兩個在該集群內,一個在集群外。
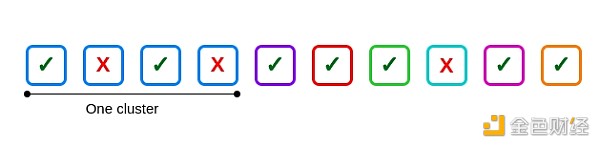
這裏有一個共同失敗:第一個集群中的第二個和第四個驗證器。 如果該集群中的所有四個驗證器都失敗了,則會出現六個共同失敗,每六個可能的對有一個。
但“應該”有多少共同失敗呢? 這是一個棘手的哲學問題。 回答的幾種方式:
對於每次失敗,假設共同失敗的數量等於該時隙中其他驗證器的失敗率乘以該集群中驗證器的數量,並將其減半以補償重復計算。 對於上面的例子,給出了2/3。
計算全局故障率,平方,然後乘以[n*(n-1)]/2對於每個集群。 這是給定的[(3/10)^2]*6=0.54
將每個驗證者的失敗隨機重新分布到其整個歷史記錄中。
每種方法都不是完美的。 前兩種方法未能考慮具有不同質量設置的不同集群。 同時,最後一種方法未能考慮到具有不同固有困難的不同時隙所產生的相關性:例如,時隙 8103681 具有大量的證明,這些證明未包含在單個時隙中,可能是因爲該塊已發布異常遲到。
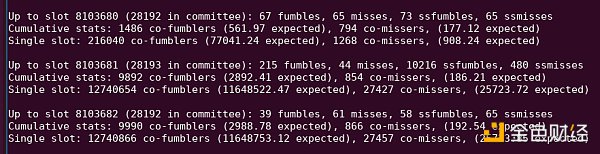
請參閱此 python 輸出中的“10216 ssfumbles”。
我最終實現了三種方法:上面的前兩種方法,以及一種更復雜的方法,我將“實際共同失敗”與“假共同失敗”進行比較:每個集群成員被替換爲(僞)隨機驗證器的失敗具有相似的故障率。
我還明確區分了失誤和錯過。 我對這些術語的定義如下:
失誤:當驗證者在當前時期錯過證明,但在上一個時期正確證明時;
錯過:當驗證者在當前時期錯過了證明並且在上一個時期也錯過了證明時。
目標是區分兩種截然不同的現象:(i) 正常運行期間出現網絡故障,以及 (ii) 離线或出現長期故障。
我還同時對兩個數據集進行此分析:最大截止日期和單槽截止日期。 僅當根本不包含證明時,第一個數據集才會將驗證器視爲在一個時期內失敗。 如果證明未包含在單個槽中,第二個數據集將驗證器視爲失敗。
以下是我對前兩種計算預期共同故障的方法的結果。 這裏的 SSfumbles 和 SSmisses 是指使用單時隙數據集的失球和失誤。
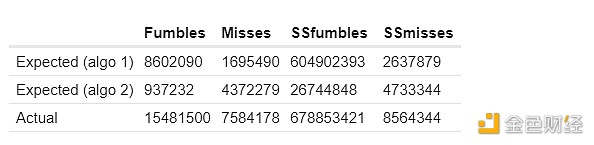
對於第一種方法,實際行有所不同,因爲爲了提高效率,使用了更受限制的數據集:

“預期”和“假集群”列顯示,如果集群不相關,基於上述技術,集群內“應該”有多少共同故障。 “實際”列顯示實際有多少共同故障。 一致地,我們看到集群內“過多相關失敗”的有力證據:同一集群中的兩個驗證器比不同集群中的兩個驗證器同時錯過證明的可能性明顯更大。
我們如何將其應用到懲罰規則中?
我提出了一個簡單的論點:在每個槽中,令 p 爲當前錯過的槽數除以最後 32 個槽的平均值。
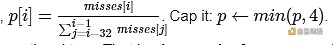
該時隙證明的懲罰應與 p 成正比。
也就是說,與其他最近的槽位相比,未證明某個槽位的懲罰應與該槽位中失敗的驗證者數量成正比。
這種機制有一個很好的特性,那就是它不容易被攻擊:在任何情況下,失敗都會減少你的懲罰,並且操縱平均值足以產生影響需要你自己進行大量的失敗。
現在,讓我們嘗試實際運行它。 以下是四種懲罰方案對大集群、中集群、小集群和所有驗證器(包括非集群)的總懲罰:
基本:每次失誤扣一分(即類似於現狀)
basic_ss:相同,但需要包含單槽才算作未命中
超額:用上面計算的 p 來懲罰 p 點
extra_ss:用上面計算的 p 來懲罰 p 點,要求單槽包含不計爲未命中

使用“基本”方案,大方案比小方案有約 1.4 倍的優勢(在單槽數據集中約 1.2 倍)。 使用“額外”方案,該值下降至約 1.3 倍(在單時隙數據集中約 1.1 倍)。 通過多次其他迭代,使用略有不同的數據集,超額懲罰方案統一縮小了“大人物”相對於“小人物”的優勢。
這是怎么回事?
每個插槽的故障數量很少:通常只有幾十個。 這比幾乎任何“大額股份”都要小得多。 事實上,它比大型質押者在單個槽位中活躍的驗證者數量還要少(即其總存量的 1/32)。 如果大型質押者在同一台物理計算機或互聯網連接上運行許多節點,那么任何故障都可能會影響其所有驗證器。
這意味着:當大型驗證者出現證明包含失敗時,他們會單槍匹馬地改變當前槽的失敗率,這反過來又會增加他們的懲罰。 小型驗證器不會這樣做。
原則上,大股東可以通過將每個驗證者置於單獨的互聯網連接上來繞過這種懲罰方案。 但這犧牲了大型利益相關者能夠重用相同物理基礎設施的規模經濟優勢。
進一步分析
尋找其他策略來確認這種影響的大小,其中同一集群中的驗證器很可能同時出現證明失敗。
嘗試找到理想的(但仍然簡單,以免過度擬合和不可利用)獎勵/懲罰方案,以最小化大型驗證者相對於小型驗證者的平均優勢。
嘗試證明此類激勵方案的安全特性,理想情況下確定一個“設計空間區域”,其中奇怪攻擊的風險(例如,在特定時間战略性地離线以操縱平均值)成本太高,不值得。
按地理位置聚類。 這可以決定該機制是否也能激勵地理上的去中心化。
通過(執行和信標)客戶端軟件進行集群。 這可以決定該機制是否也能激勵使用少數客戶。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色財經 > Vitalik:通過更多反相關激勵支持去中心化質押
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 金色財經 > Vitalik:通過更多反相關激勵支持去中心化質押
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:Vitalik:通過更多反相關激勵支持去中心化質押
地址:https://www.torrentbusiness.com/article/98746.html
標籤:質押
你可能感興趣

鐵腕SEC主席Gary Gensler 終在特朗普就任時卸職
2024/11/22 18:22
時代周刊:馬斯克如何一步步成爲“造王”者?
2024/11/22 14:53
幣安CEO寄語:帶領幣安進入加密貨幣新時代的一年
2024/11/22 14:13
低利率低通脹 特朗普變身埃蘇丹?
2024/11/22 14:07
金融巨頭策略轉變?嘉信理財進軍Crypto市場
2024/11/22 13:59