來源:元宇宙日爆
還未开放公衆測試,OpenAI憑借文本生成視頻模型Sora 制作的預告片,就把科技圈、互聯網、社交媒體圈給震驚了。
根據OpenAI官方發布的視頻,Sora能夠根據用戶提供的文本信息,生成長達1分鐘的復雜場景“超視頻”,不僅畫面細節逼真,這個模型還會模擬鏡頭運動感。
從已釋出的視頻效果看,業內興奮的正是 Sora 體現出的理解真實世界的能力。相較其他文本到視頻的大模型,Sora 在對語義理解、畫面呈現、視覺連貫性和時長上都顯示出優勢。
OpenAI 直接稱它爲“世界模擬器”,宣告它能夠模擬物理世界中的人、動物和環境的特徵。但該公司也承認,目前Sora的還不完美,依然存在理解不到位和潛在的安全問題。
因此,Sora僅對非常少數的人开放測試,OpenAI 尚未公布 Sora何時會向大衆开放,但它帶來的震撼足以讓研發同類模型的公司看到差距。
01 Sora「預告片」驚爆衆人
OpenAI文本生成視頻模型Sora一出,國內又現“震驚體”評價。
自媒體驚呼“現實不存在了”,互聯網大佬也吹爆了Sora的能力。360創始人周鴻禕稱,Sora的誕生意味着AGI的實現可能從10年縮短至兩年左右。短短幾天,Sora的谷歌搜索指數迅速拉升,熱度直逼ChatGPT。
Sora的爆火源於OpenAI 發布的48段視頻,其中時長最長的爲1分鐘。這不僅打破了此前文生視頻模型Gen2、Runway生成視頻的時長極限,而且畫面清晰,甚至它還學會了鏡頭語言。
1分鐘視頻中,一位身着紅裙的女性走在霓虹燈林立的街頭,風格寫實,畫面流暢,最令人驚豔的是女主角的特寫,連臉部的毛孔、斑點、痘印都模擬了出來,卡粉脫妝效果堪比直播關掉美顏濾鏡,脖子上的頸紋甚至精准“泄露”了年齡,與臉部狀態做到了完美統一。
除了對人物寫實,Sora還能夠模擬現實中的動物與環境。一段視頻維多利亞冠鴿的多角度特寫,超清呈現了這只鳥全身至冠的藍色羽毛,甚至細微到紅色眼珠的動態和呼吸頻率,讓人很難分清這到底是AI生成的還是人類拍攝的。
對於非寫實的創意動畫,Sora的生成效果也達到了迪士尼動畫電影的畫面感,讓網友擔憂起動畫師的飯碗。
而Sora爲文本生成視頻模型帶來的改進不僅在視頻時長與畫面效果上,它還能模擬鏡頭與拍攝的運動軌跡,遊戲的第一人稱視角,航拍視角,甚至是電影裏的一鏡到底。
看完OpenAI放出的精彩視頻,你就能理解互聯網圈、社交媒體輿論爲什么會爲Sora感到震驚,而這些只是預告片。
02 OpenAI提出「視覺補丁」數據集
那么,Sora是如何實現模擬能力的?
按照Open AI發布的Sora技術報告,這個模型正在超越先前圖像數據生成模型的限制。
以往的文本生成視覺畫面的研究採用過各種方法,包括循環網絡、生成對抗網絡(GAN)、自回歸變換器和擴散模型,但共性是集中在較少的視覺數據類別、較短的視頻或固定尺寸的視頻上。
Sora採用了一種基於Transformer的擴散模型,生圖過程可以分爲正向過程和反向過程兩個階段,以實現Sora能沿時間线向前或向後擴展視頻的能力。
正向過程階段模擬了從真實圖像到純噪點圖像的擴散過程。具體來說,模型會逐步地向圖像中添加噪點,直到圖像完全變成噪點。而反向過程是正向過程的逆過程,模型會從噪點圖像逐步恢復出原始圖像。一正一反,虛實來回,OpenAI以這種方式讓機器Sora理解視覺的形成。
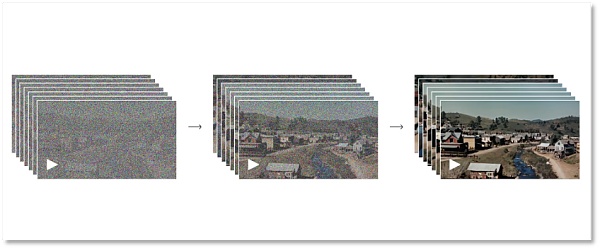 從全噪點到清晰圖的過程
從全噪點到清晰圖的過程
當然,這個過程需要反復地訓練學習,模型會學習如何逐步去除噪聲並恢復圖像的細節。通過這兩個階段的迭代,Sora的擴散模型能夠生成高質量的圖像。這種模型在圖像生成、圖像編輯、超分辨率等領域表現出了優秀的性能。
上述過程解釋了Sora能做到高清、超細節的原因。但從靜態的圖像到動態的視頻,仍需要模型進一步積累數據,訓練學習。
在擴散模型的基礎上,OpenAI將視頻和圖像等所有類型的視覺數據轉換爲統一表示,以此來對Sora做大規模的生成訓練。Sora 使用的表示方式被OpenAI定義爲“視覺補丁(patches)”,即一種更小數據單元的集合,類似於GPT中的文本集合。
研究者首先將視頻壓縮到一個低維潛空間中,隨後把這種表徵分解爲時空patch,這是一種高度可擴展的表徵形式,方便實現從視頻到patch的轉換,也正適用於訓練處理多種類型視頻和圖片的生成模型。
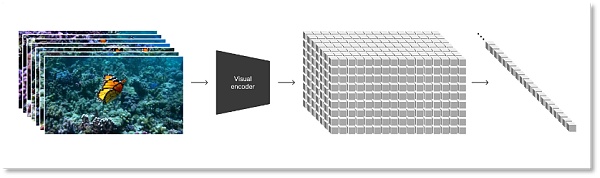 將視覺數據轉化爲patches
將視覺數據轉化爲patches
爲了用更少的信息與計算量訓練Sora,OpenAI 开發了一個視頻壓縮網絡,把視頻先降維到像素級別的地低維潛空間,然後再去拿壓縮過的視頻數據去生成 patches,這樣就能使輸入的信息變少,從而減少計算壓力。同時,OpenAI還訓練了相應的解碼器模型,將壓縮後的信息映射回像素空間。
基於視覺補丁的表示方式,研究者能對Sora針對不同分辨率、持續時間和長寬比的視頻/圖像進行訓練。進入推理階段,Sora能通過在適當大小的網格中排列隨機初始化的patches來判斷視頻邏輯、控制生成視頻的大小。
OpenAI報告,在大規模訓練時,視頻模型就表現出令人興奮的功能,包括Sora 能夠真實模擬現實世界中的人、動物和環境,生成高保真的視頻,同時實現3D一致性、時間一致性,從而真實模擬物理世界。
03 Altman當二傳手爲網友測試
從結果到研發過程,Sora顯示着強大的能力,但普通用戶還無從體驗,目前只能寫好提示詞,在X上@OpenAI創始人Sam Altman,由他作爲二傳手,幫網友們在Sora上生成視頻後放出來給公衆看效果。
這也不免令人懷疑Sora是否真的如OpenAI官方展示得那么牛。
對此,OpenAI直言,目前模型還存在一些問題。如同早期的GPT一樣,現在的Sora也有“幻覺”,這種錯誤表示在以視覺爲主的視頻結果上顯示地更爲具象。
例如,它不能准確地模擬許多基本相互作用的物理過程,例如跑步機履帶與人的運動關系,玻璃杯破碎與杯內液體流出的時序邏輯等等。
在下面這個“考古工作者們挖掘出一個塑料椅”的視頻片段裏,塑料椅直接從沙子裏“飄”了出來。
還有憑空出現的小狼崽,被網友戲稱爲“狼的有絲分裂”。
它有時也分不清前後左右。
這些動態畫面中存在的紕漏似乎都在證明,Sora仍需要對物理世界運動的邏輯去做更多的理解和訓練。此外,相比ChatGPT的風險,給人直觀視覺體驗的Sora存在的道德、安全風險更甚。
此前,文生圖模型Midjourney已經告訴人類 “有圖不見得有真相”,人工智能生成的以假亂真的圖片开始成爲謠言要素。身份驗證公司 iProov 的首席科學官紐維爾博士就表示,Sora能讓“惡意行爲者更容易生成高質量的假視頻。”
可想而知,如果Sora生成的視頻被惡意濫用,搞在欺詐和誹謗、傳播暴力和色情上,造成的後果也難以估量,這也是Sora讓人在震驚之余還會害怕的原因。
OpenAI也考慮到了Sora可能帶來的安全問題,這大概也是Sora僅對非常少數人以邀請制开放測試的原因。何時會大衆开放?OpenAI沒有給出時間表,而從官方釋出的視頻看,其他公司追趕Sora模型的時間不多了。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:還未开放 Sora怎么就震驚了互聯網圈?
地址:https://www.torrentbusiness.com/article/92507.html
你可能感興趣

一文讀懂AI智能體代幣化平台Virtuals Protocol
2024/11/21 15:19
AI 的暴力美學 Arweave 的抗衡之道
2024/11/21 14:01
鄧建鵬 李鋮瑜:加密資產交易平台權力異化及其規制進路
2024/11/21 12:33
一個跨越三輪周期的價投老VC面對這輪meme焦慮嗎?
2024/11/21 11:44
BTC已近95000 再看幣圈微笑曲线
2024/11/21 11:33