作者:油醋;來源:GenAI新世界
當庫克站在蘋果總部大樓外圍草坪的虛擬背景前开始展示全新的 iPhone 15,居住在波蘭的產品設計師 Volodymyr 轉頭拿起手機。他發了一條推特:
“我懷念喬布斯。”
這場發布會所展現出的創新力不足,而此前庫克在財報會中“生成式 AI 幾乎嵌入到我們制造的每一個產品中”的描述也沒有在新的 iPhone 身上找到任何明確的线索。喬布斯花了 2 億美元收購來的 Siri 在當時非常驚豔,現在的定位愈發模糊。
蘋果總部大樓外,生成式 AI 技術正在接近現實,蘋果也在世界各地的辦公室爲人工智能領域的研發增加崗位。但每當一種新技術即將呼之欲出,那位永遠穿着黑色高領毛衣,精於創意與集成的產品大師總是引人懷念。
1979 年,傑夫·拉斯金帶着喬布斯去位於加利福尼亞州帕洛阿爾托的研究中心 PARC 參觀。PARC 是現代個人電腦幾乎所有要素的誕生地,傑夫·拉斯金那時是研究中心的一名計算機科學家。拉裏·泰斯勒和丹·因格斯給他們演示了一種新的面向對象編程語言 SmallTalk 。
喬布斯不太喜歡系統看起來有鋸齒感的滾動方式,他問對方能否改成平滑連續的滾動方式。丹·因格斯想了想,在一分鐘內完成了代碼的改動,系統變成平滑連續的滾動方式,這讓喬布斯和所有一起來的蘋果員工大爲震驚。
不知道這是否是 20 多年後 iPhone 滑動解鎖屏幕的源頭。

這個故事被記錄在回溯文章《THE EARLY HISTORY OF SMALLTALK》裏,SmallTalk 是一門古老的編程語言,或者說是一個可以被自由編輯的操作系統。SmallTalk 的思想是,即使是非程序員也能夠將程序員开發出的應用或者組件加以修改或者組合起來,從而創造出符合自己需求的應用,另外任何人都可以直接修改SmallTalk 系統的代碼對整個系統進行自定義,系統的所有邏輯都是直接暴露給用戶的。
就像丹·因格斯爲喬布斯演示的那樣。
那個滑塊的想法是喬布斯某種超前的敏感性的一瞥,他用這種敏感攻擊着舊時代,最終帶來蘋果至今多年的繁榮。但現在蘋果的开發者人數已經超過 3400 萬人。庫克執掌下的蘋果,姿態早已由攻轉守,透出老成。而最新鮮的一批人,心思也已經不只在 iOS 商店或者 Xcode 上了。
隨着 ChatGPT 的出現,大語言模型(LLM)开始作爲一種具有現實意義的技術而被重視。
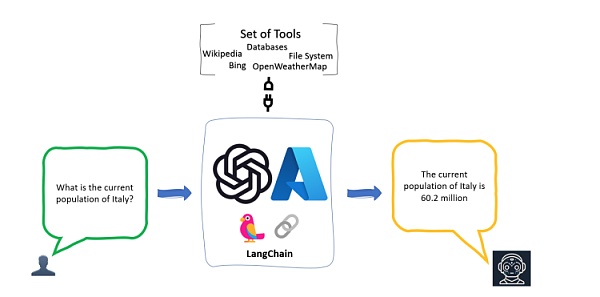
舊金山軟件公司 Robust Intelligence 的一位前機器學習工程師 Chase Harrison 在 22 年 10 月底推出了 LangChain 。這是一個封裝了大量 LLM 應用开發邏輯和工具集成的开源 Python 庫,提供了一套工具、組件和接口,允許开發者鏈接提示詞、模型和解析器,以使用底層模型創建更復雜的用例,簡化創建由大型語言模型 (LLM) 和聊天模型提供支持的應用程序的過程。
LangChain 像是 SmallTalk 的驚豔故事在40多年後的一場回歸,這樣的开發框架被形容爲“中間層”或“中間件”,正在成爲當下 LLM 應用开發者手邊最燙手的工具。
5 月 ChatGPT Pulgin 推出,以及在 6 月進一步推出的 Chat Completions API 中提供函數調用的能力,OpenAI 想要包攬一切,LangChain 的前途开始蒙上陰影。但這並不代表它會作爲一個短暫熱潮退去。“在硅谷,通用大模型的競爭已經結束,現在所有人都在談論开發 LLM 應用”,過去 3 年一直待在硅谷的蔡建說。
偉大的變革總是在浮出水面之前就已經定好商業層面上最主要的收益人(這很正常),正是微軟、谷歌和英偉達給了這場大模型變革最充分的燃料。這條主线之外,敏銳的創業者則需要找到第二落點。
但今天的一個問題是,像是SmallTalk這樣的工具和它的思想某種程度上給喬布斯這樣的非程序員提供了成功的基礎,而今天的LLM時代裏的新喬布斯們似乎還沒有得到如此的支持,依然在掙扎。
很多人开始挑战這樣的現狀,比如現在想要定義大模型軟件开發的 Harrison 和 LangChain,或者覺得 LangChain 仍然不夠銳利的蔡建和他的創業項目 ReByte 。
“中間件”還是“中間層”
生成式AI的定義權暫時聽命於 OpenAI,大模型語境下“中間件”概念第一次被廣泛關注,也出自 OpenAI 的創始人山姆·奧特曼。
“我認爲將會有一小部分的基本大模型,但對所有試圖培訓自己模型的創業公司持懷疑態度。將會發生的是,有一批新的創業公司採用已有的大模型,並對其進行調整,不僅僅是微調。中間層(Milldelayer)會變得非常重要。”去年秋季的一次 AI 討論上,山姆·奧特曼分享了對於未來的預測。
這個“中間層”的概念很容易讓人混淆,它讓人聯想到軟件時代的“中間件(Middleware)”,而奧特曼用的詞是“Middlelayer”。
“中間件包括了應用運行時、企業應用集成和各種雲服務,可以幫助开發和運維人員更高效地構建和部署應用。數據管理、應用服務、消息傳遞、身份驗證和應用編程接口(API)管理通常都要通過中間件來處理。但像 LangChain 所處的“中間層”並不是這個意思。
這是一個很少見的以所處位置的排除發來定義的概念。這么叫僅僅是因爲它既不在模型層,又不算應用層,這個“中間層”概念在大模型湧現出智能之前,並沒有合適的參照。
“所有在使用中間層這個定義的人,他們其實自己也不理解這個概念“,蔡建的理解是,這更接近一種“編排層”的概念。
LangChain 不好用
相比 LangChain ,ReByte 是一個更新的項目。
蔡建此前在豐元資本做了三年,再那之前他將一個共享文檔的創業項目“一起寫”賣給了快手。今年年初他從豐元資本位於斯坦福大學對面的辦公室走出來,聯合機器學習出身,之前在字節飛書和微軟工作過的Nemo Yang,從自己的創業團隊中撈了幾個人,組成了 7 人的創業公司 ReByte。
然後他們遇到了另一個志同道合的團隊——在 Github 上登頂過,拿到了5100顆星的 RealChar 。後者是一個對ChatGPT 背後生硬的 AI -人類溝通方式並不滿意,而希望用語音和視頻來創造兩者間更自然溝通方式的項目。蔡建以 CTO 的身份帶着團隊進入了 RealChar ,开始爲 RealChar 的技術實現提供支撐。
從 LangChain 、GPT-Index 到 ReByte ,如果用“編排層”來做定義的話,這一類項目是大模型初期基礎模型競爭的浪潮之後,將 LLM 與應用聯系起來的具體步驟。
LangChain 是最先出現的,它和後來的 GPT-Index 的理念相似,一個程序員思維的創業者想要做一個面向程序員群體的开源項目。Chase Harrison 的想法天馬行空,這也讓 LangChain 自然成爲一個非常極客的東西,有效而粗糙,拿到投資的同時, LangChain 也被很多人詬病有着太高的學習和測試成本,甚至不如自己依樣畫葫蘆的重寫一個。
ReByte 的字面意思是“重新定義寫程序這件事情”,這個項目最初發起的原因也很簡單,LangChain 不好用。
蔡建一开始想用 LangChain 做一個與餐飲平台 Yelp API 連接的訂餐系統,但最終因爲調用太麻煩,和太高的調用成本而放棄。
這件事從 LLM 到 LangChain 目前都不現實。一方面高並發狀態下多次重復請求的情況嚴重,如果只依靠LangChain 的話,爲了得到一個 API 的響應需要發送差不多 30 個請求給 OpenAI ;另一方面, LLM 本質上是面向普通用戶和自然語言的,沒有特別爲 API 調用而做的設計,生成的 API SPEC 過長,以Token數折算成花費將是一個天文數字。
“但這實際上不是 LLM 自己的問題”,蔡建說。
LLM 的理解和推理能力能夠完成一個目標任務的拆分,比如把一個大的目標實現拆分成多個任務,然後在這些步驟中尋找優先級最高的任務,繼續往下拆分,直到形成整個任務流程。
“理論上只要你給他個目標,他可以無限的循環,然後非常理想的情況,它一定可以把這事情做完。”
但這種忽視時間尺度的“理想化”本身缺乏現實意義。要解決實際問題的話,答案需要在一個相對明確的時間範圍裏給出,並且在安全性和成本上可控。
在 LLM 湧現出智能之前,所有的軟件產品都需要軟件工程師按照需求一行一行來寫,而人們期待的人工智能,只需要你明確的描述出來你要做什么,它就可以幫你解決所有行業問題。
以現在的視角來看,之前的軟件時代,與人們對未來 LLM 成熟形態的期待,在一場關於計算機的想象的兩個極端。ReByte 則希望在這中間取得一個折中的位置。
這聽起來近似於行業大模型的概念,這把能讓 LLM 快速落地的萬能鑰匙引得幾乎所有大模型公司趨之若鶩。但這中間也有一個實際的路线問題,到底是在應用層面加入行業數據,還是在模型訓練層面加入行業數據?
蔡建更傾向前者,即大模型本身並不需要理解行業知識,需要行業知識的是應用。
“每個公司都在說我要做行業大模型,不是因爲他懂大模型,而是因爲他懂這個行業。”
最終來看,只有調用 LLM 的成本足夠低,它才能變得實用。一種可能性是,如果有太多行業知識的雜質參與到模型訓練中,每一個 Query (查詢請求)都會浪費掉更多的計算。而知識如果從基礎模型外部灌輸進來可能是更靈活的方式。LLM 本身需要高度具備常識,即推理能力等抽象化的思維能力,但一個 HR 系統,一個醫療系統或者一份修車手冊不該成爲常識的一部分。
於是 ReByte 不改造 LLM ,而是要做一個連接 LLM 的低代碼平台,以及一個灌入數據的接口。
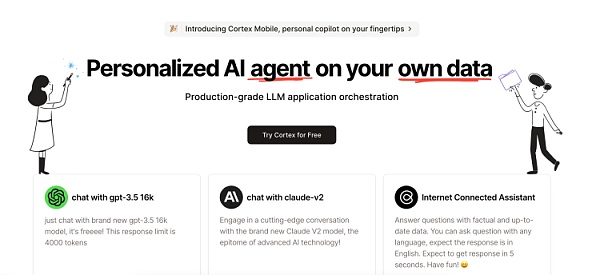
在 ReByte 的使用方式上,主要分爲 Copilot 和 Callables(可調用)兩類工具。前者可以直接進入使用, 接入了ChatGPT、Claude 的底層模型能力,也引入了即時搜索、文檔概括的功能,甚至結合了 NBA 這樣特殊的數據庫做了對話產品。但 Copilot 更像是 ReByte 爲了 Callables 做的展示。ReByte 爲使用者提供了連接 LLM 的开發流程和工具,並且提供了數據庫導入的途徑。
美國 SaaS 市場相對完善,目前 ReByte 已經和 Notion 、Google Drive 、Slack 、Discord 等 SaaS 平台建立連接。企業數據通過API接口接入後,RealChar 對其進行向量化的處理,然後喂給做好的工具,生成自己的 Agent 。
至於這個 Agent 是叫 Copilot 或是其他什么應用,只是表現方式的區別。
技術降維和它的代價
所有用過 LangChain 的开發者都不會否認,這個框架透露出一些技術狂的自嗨,這無形中鑄造了很高的技術門檻。LLM 本質上卻是一種技術降維,如果你有一個好的想法並且又清晰且有效的解決邏輯——比如喬布斯的天才想法碰上 SmallTalk —— LLM 可以成爲聽憑吩咐的萬能打手。
ReByte 與 LangChain 在出發點上的差異,可能是前者對這種技術降維更加樂觀,或者說在當下具有更大的野心。
ReByte 最初的項目團隊裏,兩個人在美國做業務拓展,國內有一支經驗成熟的 4 人开發團隊,另外的一位員工來自印度。這位印度員工非常年輕、有很強的編程能力,充滿編程熱忱。從招募進來到現在,他負責了團隊裏接近一半的代碼產出,但蔡建從來沒有見過他。
這個印度开發者是 ReByte 團隊 在 GitHub 上無意間看到的一個好項目的歸屬者,然後聯系了他,很快團隊裏多了一位遠程辦公的新成員。這樣具有精英級代碼能力的开發者鳳毛麟角,但隨着 LLM 的出現,未來對开發者的定義或許可以完全拋开寫代碼這件事。
就像足夠精確的 Prompt 可以在 Midjourney 上實現你所有想要的視覺效果一樣,當 LLM 可以在寫代碼層面代替人類後,开發者的核心能力就變成了教會 LLM 以什么方式寫代碼,以及每一步所要達成的訴求是什么。這更像是一種前面提到的“編排”能力, 而“編排”的高低,最終考驗的東西也從代碼能力轉變爲更本質的邏輯能力以及對場景的理解程度。
在這兩方面具有優勢的人,在軟件時代可能會被具體的代碼難題卡住,但未來可依靠 LLM 寫出一個完整的軟件系統。
他們會是新的應用开發者,微軟 CEO 薩蒂亞·納德拉對這個新的开發者群體的預測是 10 億人。在此之前,互聯網創業的邏輯無非是 ToB 或 ToC 之間的選擇,但隨着未來开發者的技術門檻降低,這兩條路线未必是 LLM 創業的唯一准則。开發者群體本身會變成一個巨大市場。
ReByte 的走向是“ To 开發者”。甚至未來所有“編排層”的工具都會爲這個群體服務。
這樣的變化也牽引着創業者的變化。李彥宏在文心一言發出時預先替所有創業潑了一盆“大模型創業沒有機會”的冷水,但隨着开發者門檻的下降,更加九死一生的應用層創業或許也只是大公司安撫人心的說辭一種。
不是那個一呼百應的時代了
我們在很多事情上都有相似的體驗。比如一群人的抖音上火透了的“秀才”直到被封都從未進入過另一群人的信息流裏;比如 Hugging Face 正在成爲开源大模型的核心社區,但大模型這個詞仍然讓大部分人感到陌生。
人們對自己的喜好越來越明確,需求也越來越精細。如果在 10 多年之前那個 iPhone 引領的移動互聯網形成時期(或者更早),好的創意可以不斷做大,然後變成一家 Meta 、字節跳動這樣的公司,現在這樣的事越來越少了。
“技術門檻降低,一個开發者能做的東西其實也同時會非常有限,它很小、很具體、非常個性化。”
生成式 AI 如果真的能形成一股長久的技術浪潮,那圍繞它創業的殘酷時代背景,是一個好的創意更難變成一個創業公司,一個小的應用只能解決某一小撮人的問題,蔡建認爲這是开發者門檻降低的代價。
“未來越來越多分散的开發者會出現,他們會在一些小的領域做一些更固定的事,憑借一些特別的數據或者行業Knowhow ,然後靠這個賺錢。這個時代已經不是一個一呼百應,找一群人來做大公司的時代了。”
所以有價值的事情就沉到了更基礎的地方——誰能給他工具讓他做這樣的事情,而不是做應用這件事本身。
就像喬布斯在多年前所說的:It's more fun to be a pirate than to join the navy。
“與其加入海軍,不如成爲海盜。”
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:大模型時代的喬布斯怎么還沒來
地址:https://www.torrentbusiness.com/article/70690.html
你可能感興趣

鐵腕SEC主席Gary Gensler 終在特朗普就任時卸職
2024/11/22 18:22
時代周刊:馬斯克如何一步步成爲“造王”者?
2024/11/22 14:53
幣安CEO寄語:帶領幣安進入加密貨幣新時代的一年
2024/11/22 14:13
低利率低通脹 特朗普變身埃蘇丹?
2024/11/22 14:07
金融巨頭策略轉變?嘉信理財進軍Crypto市場
2024/11/22 13:59