今年,GPT、AI繪畫等人工智能大模型工具火熱,許多人也想來追一波AI創業熱潮,相關創業項目層出不窮。優質數據對AI大模型訓練至關重要,只有擁有足夠多的數據,才能訓練出智能、強大的AI工具。我國互聯網蓬勃發展二十余年,還能缺少數據?這不,曼昆律師最近接到網友咨詢,准備用爬蟲爬取知乎數據,做一個知乎GPT機器人豈不美哉?且慢,這其中的法律風險不可忽視。
01 爬蟲是把雙刃劍
爬蟲技術是一種通過編程自動從互聯網上獲取數據的技術。它的名字形象、生動地表明了它的工作原理:模擬人類在網頁瀏覽器中瀏覽網頁的過程,進行數據採集和數據抓取。
網絡爬蟲廣泛應用於搜索引擎、數據採集、廣告過濾、大數據分析等領域。作爲一種功能強大的信息採集程序,它能夠顯著提高工作效率,尤其是對海量數據的收集和整理。
然而,一旦技術被不正當使用,也會引發“蟲災”,導致網絡擁堵、崩潰、服務器癱瘓甚至引發數據安全風險。我們熟悉的“裁判文書網”也不能幸免:

圖:2019年,最高人民法院發布的《關於“中國裁判文書網”網站建設建議的答復》
02 使用爬蟲技術的風險
爬蟲作爲一項獲取數據的技術手段,並未被法律禁止。但使用方式及使用目的決定了是否會產生違法的行爲和後果。
1.使用方式不當
使用爬蟲技術, 能在短時間內對網站進行大量訪問,頻繁抓取頁面和數據。這可能會導致網站的帶寬和服務器負載急劇增加,從而影響網站的正常運行,甚至導致宕機或響應緩慢,幹擾被訪問網站的正常運營,嚴重時可構成犯罪。
楊某授權公司員工張某开發某信貸系統軟件,該軟件內的“網絡爬蟲"功能能與深圳市居住證網站鏈接。2018年5月,該軟件連續兩小時對深圳市居住證系統查詢大量訪問,致使深圳市居住證系統無法正常運作,極大地影響了該居住證系統使用方深圳市公安局人口管理處的日常運作。二人均構成破壞計算機信息系統罪。【(2019)粵0305刑初193號】
2.使用目的不當
與使用方式相比,如何使用爬取的信息和數據,對爬蟲行爲的定性影響更大。
非法使用爬取的數據和信息主要有:
(1)盜取個人信息:使用爬蟲技術惡意抓取網站上的個人信息,可能涉及侵犯他人隱私、個人信息,嚴重可構成侵犯公民個人信息罪。

(2)商業競爭中的不正當行爲:使用爬蟲技術獲取競爭對手的商業祕密、定價信息、用戶數據等,對數據整合後“搬家”到其他平台,通過這種便捷的方式獲取大量有價值的數據、信息,以謀取不正當競爭優勢。
在“酷米客訴車來不正當競爭糾紛案”中,法院認爲,未經權利人許可,利用網絡爬蟲技術進入權利人的服務器後台的方式非法獲取並無償使用權利人的實時公交信息數據的行爲,實爲一種“不勞而獲”、“食人而肥”的行爲,且具有非法佔用他人無形財產權益,破壞他人市場競爭優勢,構成不正當競爭。
(3)侵犯知識產權:爬取受版權保護的內容,然後用於未經授權的公开傳播或商業用途,屬於侵犯知識產權的行爲。


03 爬蟲數據“投喂”大模型的風險
通過前面的分析可知,使用爬蟲技術的風險主要在於爬取的方式以及爬取的內容,那是不是控制爬取的頻率和內容,爬取公开內容,用來訓練機器人就沒有什么風險了呢?
首先,知乎官方账號早在2018年就發布了《關於知乎用戶權益保護升級的公告》,提到:知乎對第三方开放知乎內容的使用採取白名單制,第三方需要通過官方合作渠道進行申請。如果爬取行爲違反了知乎的服務條款,知乎可能採取封禁账號、IP地址或者其他法律行動。
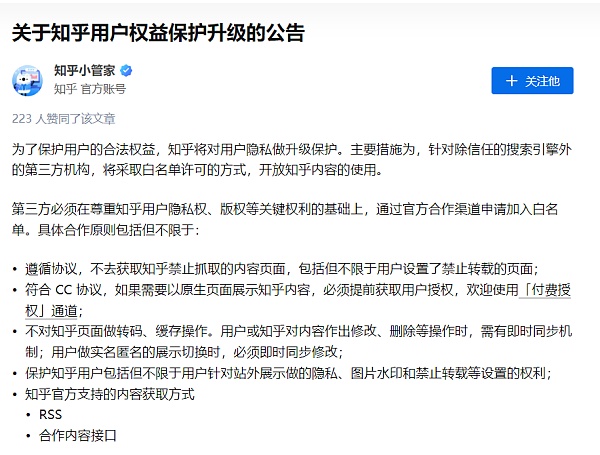

摘自《知乎機構號使用規範》(試行)
其次,知乎上的內容通常由用戶原創或授權發布,著作權歸用戶本人所有。未經授權地爬取和使用這些內容,可能涉及侵犯知乎的版權和著作權。

其實,訓練AI大模型,“數據盜竊”並非個案。上個月,筆神作文公开指控昔日合作夥伴學而思,認爲學而思通過爬蟲方式“偷數據”訓練自家AI產品。筆神作文表示,將通過司法程序解決糾紛,要求“學而思”支付1元賠償金,公开道歉,並刪除已爬取的數據。

04 小結
在人工智能創業的熱潮中,數據變得越來越重要。在面對爬蟲技術帶來的誘惑時,應當認識到,雖然爬蟲技術本身並未被禁止,但其不當使用可能導致法律問題,尤其是在涉及個人信息、隱私、版權和不正當競爭等方面。
《生成式人工智能服務管理暫行辦法》中明確提到,訓練數據處理活動時,應當使用具有合法來源的數據和基礎模型。各位老板在創業過程中,要確保數據採集的合法性和道德性。如果想要使用爬取的數據訓練AI大模型,務必事先獲得數據來源方的授權,並遵守相關平台的規定。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:AIGC創業 用爬蟲技術做個知乎版GPT機器人合法嗎?
地址:https://www.torrentbusiness.com/article/55495.html
你可能感興趣

一文讀懂AI智能體代幣化平台Virtuals Protocol
2024/11/21 15:19
AI 的暴力美學 Arweave 的抗衡之道
2024/11/21 14:01
鄧建鵬 李鋮瑜:加密資產交易平台權力異化及其規制進路
2024/11/21 12:33
一個跨越三輪周期的價投老VC面對這輪meme焦慮嗎?
2024/11/21 11:44
BTC已近95000 再看幣圈微笑曲线
2024/11/21 11:33