在智能合約領域,"以太坊虛擬機 EVM" 以及其算法和數據結構就是第一性原理。
本文從合約爲什么要分類出發,結合每個場景可能面對怎樣的惡意攻擊,最終給出一套達成相對安全的合約分類分析算法。
雖然技術含量較高,但亦可作爲雜談讀物,一覽去中心化系統間博弈的黑暗森林。
1、合約爲什么要分類?
因爲太重要了,可謂是交易所、錢包、區塊鏈瀏覽器、數據分析平台等等 Dapp 的基石!
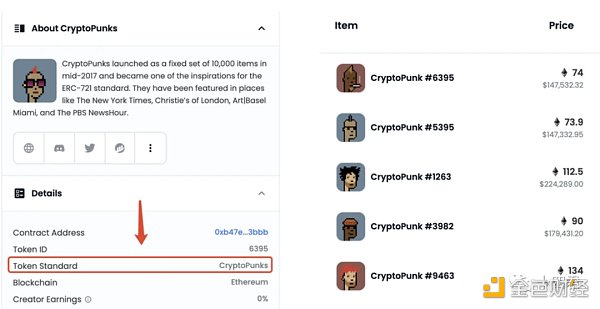
一筆交易之所以是 ERC 20 轉账,是因爲他的行爲符合 ERC 20 標准,至少得有:
交易的狀態是成功
To 地址爲某個符合 ERC 20 標准的合約
調用了 Transfer 函數,其特點是該交易 CallData 的前 4 位爲0x a 9059 cbb
執行後,在該 To 地址上發出了transfer的事件
分類有誤則交易行爲會誤判
以交易行爲爲基石,則 To 地址能否被准確分類則對其 CallData 的判斷會有截然不然的結論。對 Dapp 而言,鏈上鏈下的信息溝通高度依賴於交易事件的監聽,而同樣的事件編碼也只有在符合標准的合約中發出,才具有可信度。
分類有誤則交易會誤入黑洞
如果用戶進行一筆 Token 轉移,轉入到某個合約中,如果該合約沒有預設 Token 轉出的函數方法,則資金會雷同於 Burn 一樣被鎖定,無法控制
且如今大量項目开始增加內置的錢包支持,要爲用戶管理錢包也就不可避免的,需要時刻從鏈上實時分類出最新部署的合約,是否能夠吻合資產標准。
2、分類會有怎樣的風險?
鏈上是一個沒有身份沒有法治的地方,你無法制止一筆正常的交易,哪怕他是惡意的。
他可以是冒充外婆的狼,做出多數符合你預期的外婆行爲,但目的是進屋搶劫。
聲明標准,但可能實質不符合
常見的分類方式是直接採用 EIP-165 標准,讀取該地址是否支持 ERC 20 等,當然,這是一個高效率的方法,但是畢竟合約是對方控制,所以終究是可以僞造出一份申明。
165 標准的查詢,只是在鏈上有限的操作碼中,用最低成本去防止資金轉入黑洞的方法。
這也是爲什么我們之前分析 NFT 的時候,特地提及標准中會有一類SafeTransferFrom的方法,其中Safe就是指代了採用 165 標准判斷出對方聲明自己具備了 NFT 的轉移能力。
唯有從合約字節碼出發,做源碼層面的靜態分析,從合約預期的行爲出發才有更精准的可能性。
3、合約分類方案設計
接下來咱們將系統的分析整體方案,注意我們的目的是“精度”和“效率”兩項核心指標。
要知道即使方向是對的,但要抵達大洋的彼岸路途也並不明朗,要做字節碼分析的第一站是獲取代碼
3.1、如何獲取到代碼?
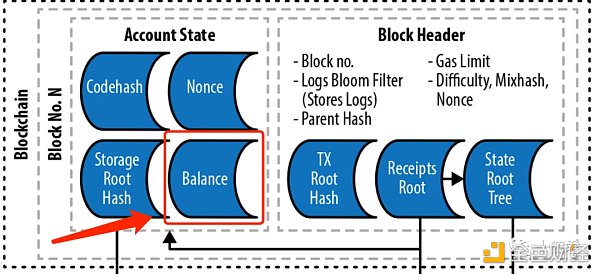
從上鏈後的角度講有getCode,一個 RPC 方法,可以從鏈上指定的地址裏獲取到字節碼,單論讀取的話這是非常快捷的,因爲從 EVM 的账號結構中就把 codeHash 放在最頂端的位置。
但是這個方法等於是單獨對某個地址做獲取,想要進一步提升精度和效率呢?
如果是部署合約的交易,如何在其剛執行完甚至他還在內存池中便獲取部署的代碼?
如果該筆交易是合約工廠的模式,則交易的 Calldata 裏是否存在源碼呢?
最後的我的方式是,是分類進行一種類似篩子的模式
對於非合約部署的交易,則直接用getCode獲取其中涉及的地址進行分類,
對於最新內存池的交易,篩選出 to 地址爲空的交易,其 CallData 則是帶有構造函數的源代碼
對於合約工廠模式的交易,由於其中可能是合約部署出的合約再循環調用其他合約來執行部署,則遞歸的去分析該筆交易的子交易,記錄每個 type 爲CREATE或者爲CREATE 2 的 Call。
我做了個 demo 實現的時候,發現還好現在 rpc 的版本比較高,因爲整個過程最難的便是執行 3 的時候,如何遞歸找到指定 type 的 call,最底層的方式是通過 opcode 還原上下文,我喫了一驚!
還好現在的 geth 版本裏有debug_traceTransaction 方法,他可以幫助解決在通過 opcode 操作碼中梳理每一個 call 的上下文信息,整理出核心的字段。
最終可以對多種部署模式的(直接部署,工廠模式單部署,工廠模式批量部署)的原始字節碼都獲取到。
3.2、如何從代碼分類?
最最簡單但不安全的方式,是把 code 直接做字符串匹配,以 ERC 20 爲例符合標准的函數則有

在函數名之後的,則是該函數的函數籤名,之前在分析的時候提及,交易都是依賴匹配 callData 的前 4 位找到目標函數的,拓展閱讀:
所以合約字節碼裏必然存儲有這 6 個函數的籤名。
當然,這種方法非常快捷 6 個都查到就完事的,但不安全的因素則是,如果我採用 solidity 合約中,單獨設計一個變量,存儲值爲0x 18160 ddd 那么他也會將認爲我有了這個函數。
3.3、准確率提升 1-反編譯
那進一步的准確方法則是做 Opcode 的反編譯!反編譯則是將獲取到的字節碼轉到操作碼的過程,更高級的反編譯則是再轉成僞代碼,更利於人的閱讀,這次我們用不上,反編譯的方法列於文末的附錄中。
solidity(高級語言)->bytecode(字節碼)->opcode(操作碼)
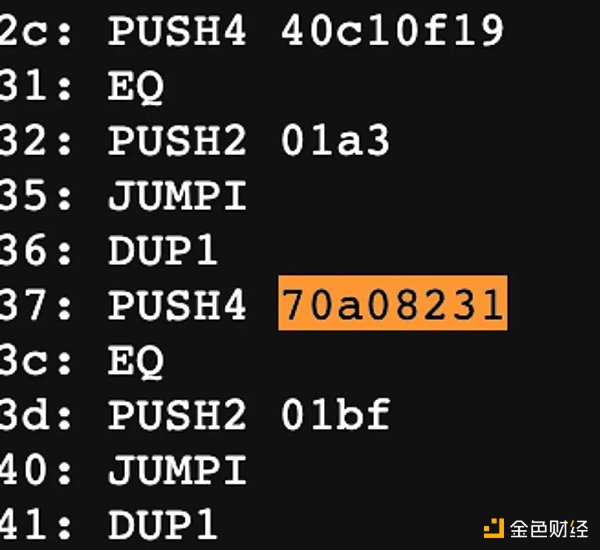
我們就可以清晰的發現一個特徵,函數籤名都會被PUSH 4 這個操作碼所執行,所以進一步的方法則是從全文中提取PUSH 4 後的內容,與函數標准做匹配。
我也簡單做了下性能實驗,不得不說 Go 語言的效率很強大, 1 W 次反編譯只需要 220 ms。
接下來的內容會有一定難度
3.4、准確率提升 2-找代碼塊
上文中准確率有所提升但還不夠,因爲是全文搜索PUSH 4 的,因爲我們仍然可以構建一個變量,是byte 4 的類型,這樣一來也會觸發PUSH 4 的指令。
在我苦惱的時候,想到一些开源項目的實現,ETL 是一個讀取鏈上數據做分析的工具,其中會解析出 ERC 20、 721 的轉移單獨成表,所以必然具備分類合約的能力。
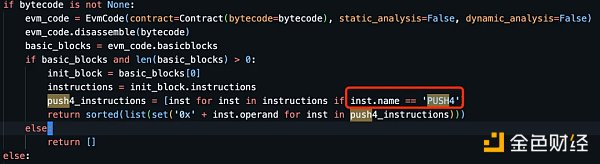
分析下來,可以發現他是基於代碼塊的分類,只處理第一個basic_blocks[ 0 ]裏的push 4 指令
那問題來到了,如何准確判斷代碼塊了
代碼塊的概念源於REVERT + JUMPDEST 這 2 個連續的操作碼,這裏必然需要連續的 2 個,因爲在整個函數選取器的 opcode 區間裏,如果函數數量過多,則會出現翻頁的邏輯,那也會出現JUMPDEST 這個指令。

3.5、准確率提升 3-找函數選擇器
函數選擇器的作用是,讀取該筆交易的 Calldata 的前 4 位字節,並與代碼中預設有的合約函數籤名進行匹配,協助指令跳轉到存儲了該函數方法指定的內存位置
讓我們嘗試一個最小的模擬執行
這部分是兩個函數的選擇器store(uint 256)和retrieve(),可算出籤名是2 e 64 cec 1 , 6057361 d

進行反編譯後,則會得到如下的操作碼串,可以說分兩個部分
第一部分:
在編譯器中在合約中僅函數選擇器部分會去獲取到 callData 的內容,寓意是獲取其 CallData 的函數調用籤名,注釋如下圖。

我們可以通過模擬 EVM 的內存池變化來看看效果
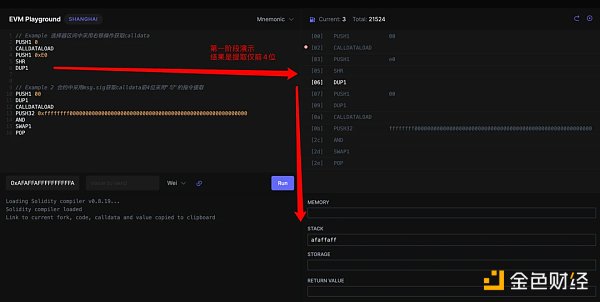
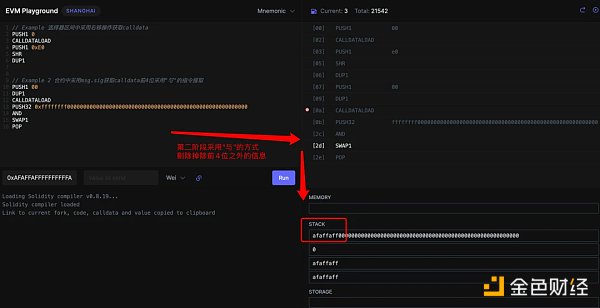
第二部分:
判斷是否與選擇器的值匹配的過程
1、將 retrieve()的 4 字節函數籤名(0x 2 e 64 cec 1)傳入 stack 上,
2、EQ 操作碼從 stack 區彈出 2 個變量,即0x 2 e 64 cec 1 和0x 6057361 d,並檢查它們是否相等
3、PUSH 2 將 2 個字節的數據(這裏爲0x 003 b,十進制爲 59)傳入 stack,stack 區有一個叫做程序計數器的東西,它規定了下一個執行命令在字節碼中的位置。這裏我們設置 59 ,因爲那是 retrieve()字節碼的起始位置
4、JUMPI 代表"如果...,則跳轉至...",它從 stack 中彈出 2 個值作爲輸入,如果條件爲真,程序計數器將被更新至 59 。
這就是 EVM 是如何根據合約中的函數調用,來確定它需要執行的函數字節碼的位置的原理。
實際上,這只是一組簡單的“if 語句”,用於合約中的每個函數以及它們的跳轉位置。

4、方案總結
整體簡述如下
每個合約地址可以通過 rpc getcode 或者debug_traceTransaction,獲取到部署後的bytecode ,採用 GO 中 VM 和 ASM 庫,反編譯後即獲取到opcode
合約在 EVM 運行原理中,會有以下特徵
採用REVERT+JUMPDEST這 2 個連續的 opcode 作爲代碼塊的區分
合約必然具備函數選擇器的功能,該功能也必然在第一個代碼塊上
函數選擇器中,其函數方法均採用PUSH 4 作爲 opcode ,
該選擇器所包含的 opcode 中,會出現連續的PUSH 1 00; CALLDATALOAD; PUSH 1 e 0; SHR; DUP 1 ,核心功能是加載 callDate 數據並進行位移操作,從合約功能上其他語法不會產生
3. 對應的函數籤名在 eip 中定義,並且有必選和可選的明確說明
4.1、唯一性證明
走到這裏我們就可以說,基本實現高效率,高准確率的合約分析方法了,當然既然已經嚴謹了這么久,不妨再嚴謹一些,我們上文方案裏中基於 REVER+JUMPDEST 來做代碼塊的區分,結合其中必然的 CallDate 加載和位移來做唯一性判斷,那是否存在,我可以用 solidity 合約也實現出類似的操作碼序列呢?
我做了下對照實驗,從 solidity 語法層面雖然亦有 msg.sig 等獲取 CallData 的方法,但編譯後其 opcode 的實現方法不同
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:深入EVM-合約分類這件小事背後的風險
地址:https://www.torrentbusiness.com/article/43861.html
標籤:EVM
你可能感興趣

一文讀懂AI智能體代幣化平台Virtuals Protocol
2024/11/21 15:19
AI 的暴力美學 Arweave 的抗衡之道
2024/11/21 14:01
鄧建鵬 李鋮瑜:加密資產交易平台權力異化及其規制進路
2024/11/21 12:33
一個跨越三輪周期的價投老VC面對這輪meme焦慮嗎?
2024/11/21 11:44
BTC已近95000 再看幣圈微笑曲线
2024/11/21 11:33