在產品建設方面,數據所有權轉移已迅速成爲需要解決的關鍵問題之一。社交媒體平台濫用數據的現象頻發,我們亟需建立方案來解決這一問題。鑑於此,區塊鏈提供了一種功能,可以永恆地存儲、轉移數據,並創建市場,允許用戶將其數據貨幣化。
區塊鏈,首先是一種技術。取決於某個生態系統試圖解決什么問題,技術的實施方案可以有很大的不同。一些區塊鏈試圖專注於性能,以可能取代傳統的基礎設施(例如,VISA每秒可以處理12,000筆交易),而其他區塊鏈則把隱私作爲金融基礎設施的主要組成部分。是的,在全球範圍內,任何區塊鏈的核心都是具有一定存儲能力的區塊,當被填滿時,會被關閉並與之前填滿的區塊相連,形成一個被稱爲區塊鏈的數據鏈,但區塊鏈之間的存儲組織本身可以有根本的不同。以太坊的所有商業邏輯主要是通過智能合約實現的,而例如在波爾卡多,則是通過托盤來實現的。是的,即使糾結於同樣的智能合約,比較一下,例如以太坊和Solana,首先,它們是用不同的編程語言編寫的(以太坊是Solidity,Solana是RUST | C | C++),其次,它們實現的存儲方法完全不同。
需求產生供給,隨着使用Web3 數據的需求逐漸增加,爲用戶提供數據的平台也越來越受歡迎。大部分新數據平台,都是盡量降低入門門檻,盡量讓开發者和分析師都滿意。數據創業公司遵循的目標有很多,但最重要的也許是數據模型,因爲用戶的使用體驗、查詢執行速度和其他關鍵指標都取決於它。
本文將探討 Footprint Analytics 的數據模型和目前最受歡迎的分析平台 Dune Analytics 提供的數據模型之間的實施差異。
處理區塊鏈數據的平台有一個類似的ETL過程。這個過程的步驟是:
節點提供者將數據傳輸給索引器
處理原始數據
對原始數據進行抽象化
視覺化
在下面的部分,我們將更詳細地研究每個步驟,並指出每個平台內實施的差異。
--- **NOTE** - 爲了簡單起見,下面所有的例子都是基於 EVM 鏈的--V2 版的 Dune 作爲比較對象。 更多詳情請見 - [Dune V2 - Dune Docs](https://dune.com/docs/reference/dune-v2/.) —
節點提供者向索引器傳輸數據
節點提供者是一個 "客戶端 "軟件,將它們連接到區塊鏈的網絡,使它們能夠在其他節點之間來回發送信息,在某些情況下,驗證交易和存儲數據。爲了接收這個 "新區塊創建 "信息,必須有人運行一個區塊鏈節點。爲了確保新交易有足夠高的處理速度,挑選一個可靠的 RPC 至關重要。對於節點提供方,我們所對比的這兩個平台都是閉源的,所以很難說他們正在使用哪個節點提供者,或者是否自建節點。但大部分數據平台通常遵循的是一種混合選項:既使用節點提供者,又使用部署的本地節點。
處理原始數據
作爲下一步,從節點提供者那裏收到包含區塊鏈交易數據的哈希字節碼。該字節碼被解碼並以原始形式保存。如果你曾經使用過[[block explorer]],你應該知道某個區塊鏈所持有的原始數據。這些細節在不同的鏈之間是不同的,但是作爲一個例子,大多數由以太坊虛擬機(EVM)驅動的鏈包括:
Blocks - 附加在鏈上的交易組
Transactions - 加密籤名的區塊鏈狀態指令
Logs - 由智能合約創建的事件
Traces - 記錄交易執行過程中發生的每一個事情
實際上,上述實體構成了區塊鏈的全部內容。這表明,僅通過使用它們,任何去中心化的生態系統可能已經被充分分析。盡管這些表中的數據可以由人類讀取(與字節碼不同),但需要對區塊鏈有深刻的理解。該平台將上述實體存儲到以下表格中,作爲ETL程序的一部分:
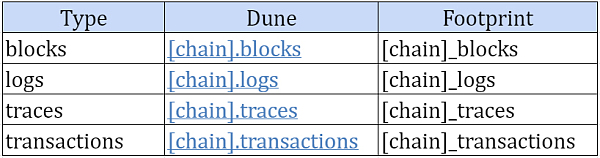
兩個平台上的表數據,幾乎都有相同的列,所以不同的查詢可以基本上在平台之間重復使用。
數據解碼
任何 EVM 區塊鏈上的大多數智能合約都是使用 Solidity 等高級編程語言創建的。它們必須被編譯成 EVM 可執行字節碼,然後才能在 EVM 執行環境中使用。一旦部署,字節碼將永久存儲在鏈的狀態存儲中,並分配給一個特定的地址。
客戶端應用程序需要一個指南來調用高級語言中定義的功能,以便能夠與這個智能合約進行互動,目前它只是字節碼。一個應用二進制接口(ABI)被用來將名稱和參數翻譯成字節形式。ABI 正確記錄了名稱、類型和參數,允許客戶端應用程序以人類相對可讀的方式與智能合約溝通。可以利用高級編程語言的源代碼來編譯 ABI。TLDR:要調用智能合約或破譯其產生的數據,請使用 ABI。
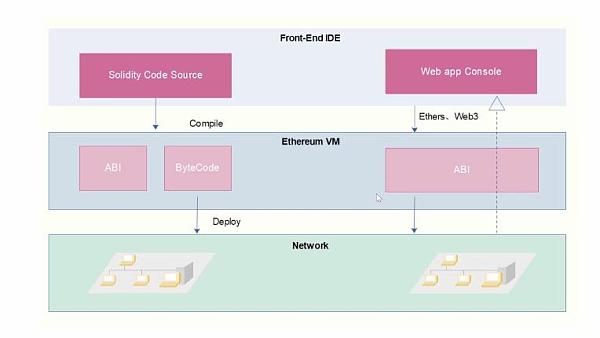
爲了允許對正在發生的事情進行後向分析,區塊鏈被設計爲分析和存儲事件。智能合約通過交易和消息調用發出過程中的事件,相互溝通。因此,查看事件通常是分析區塊鏈上發生的各種事情的最簡單和最方便的方法。
然而,偶爾會有重要的信息從發出的事件中被遺漏,或者根本沒有事件。在這種情況下,分析師可能不得不求助於交易和消息調用(在原始表格中發現)。隨着時間的推移,沒有事件被發出的情況越來越少,因爲現在的开發人員大多明白,事件對分析的重要性。但目前還是仍然存在遺漏的情況。在某些情況下,將解碼後的數據與原始數據結合起來,以獲得關於交易的元數據或更深入地研究,是有意義的。
Dune
對於要解碼並添加到 Dune 數據集的合約,可以使用以下表格。智能合約上傳表格 一旦合約被解析,與特定智能合約相關的調用和事件正在被保存到相應的表格中。
Calls
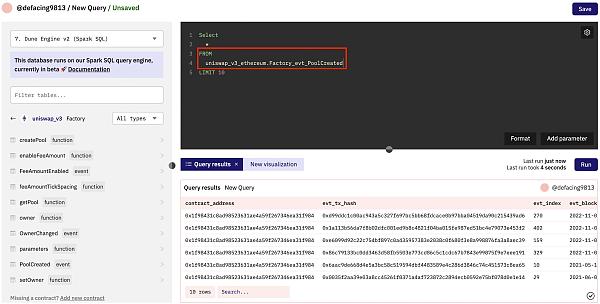
通常情況下,一個智能合約將有可能被另一個智能合約或外部擁有的账戶(EOA)調用的功能。從直接的狀態讀取和返回到修改幾個狀態並觸發對其他智能合約的消息調用,函數可以是任何東西。對智能合約的每一個消息調用和交易都可以在 Dune 上被解析爲它們自己的表。然後,這些表被賦予以下名稱:
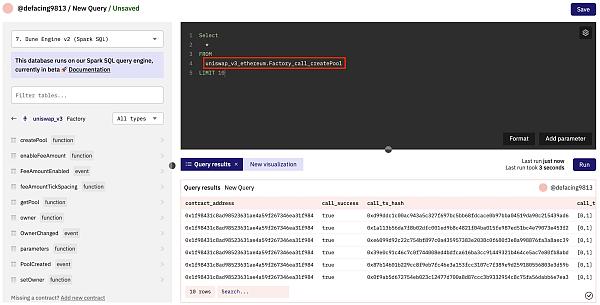
Screenshot 2022-11-21 at 13.20.30.png
Events
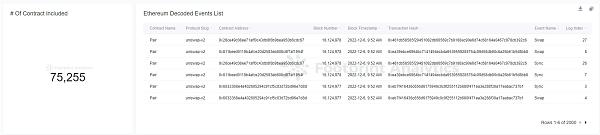
事件日志是由智能合約在完成特定的預先定義動作時產生的。智能合約开發者已經預先定義了這些日志的結構,而內容是在整個交易過程中動態創建的。日志有助於跟蹤智能合約內部的活動,並用於監測、警報和其他目的。
Screenshot 2022-11-21 at 13.21.47.png
Footprint
截至發稿時,Footprint 目前已支持 Ethereum 存儲調用和事件的表。而其它公鏈的底層原始數據,連同 ABI 提交、合約解析需求提交,計劃在2022年底前發布。
對原始數據進行抽象化
將原始數據轉化爲有洞察力的信息絕不是一件小事。雖然艱難,但並不是不可行的。建立和微調 ETL 模型只是許多數據企業家每天進行的工作中的一小部分。在試圖轉換原始數據的系統設計中,包括以下規格:
數據表,可以實時連續分析來自歷史和實時的數據流,大大簡化了生產數據科學的工作流程。
模式的執行,使表保持整潔有序,沒有列的污染,並爲機器學習做好准備。
模式演進,使現有的數據表增加新的列,而不會在生產中使用這些表時導致其中斷。
數據版本,這使得審計、復制,甚至在必要時回滾任何Delta Lake表的變化,以避免人爲錯誤帶來的意外變化。
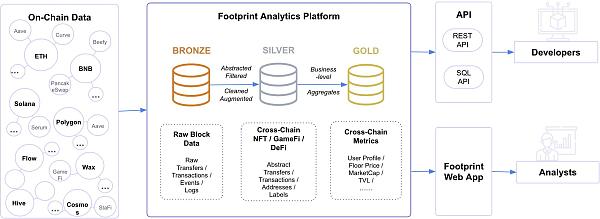
數據攝取("銅")、轉換/特徵开發("銀")和業務匯總("金")是典型 ETL 的三個階段,它們採用的表格與數據工程管道中的各種質量等級相關。這些表格一起被稱爲 "金銀銅 "架構。
它使數據工程師能夠創建一個流程,從未經處理的數據开始,並作爲 "單一源",其他一切都通過它流動。即使下遊用戶清理了數據並添加了特定的上下文結構,也可以計算和檢查進一步的轉換和匯總,以確保業務層面的匯總表仍然反映基礎數據。Dune 和 Footprint 都在工作流程中實施了以下方法,但形式上有很大的不同。
Dune
銀以及金數據表在 Dune V2 上是使用魔法表(Spellbook)構建的. Spellbook 是一個社區構建的層。通過創建復雜的表的指令,處理廣泛使用的用例,如NFT交易。抽象可以被物化爲視圖和表,但也有許多可能的細化,包括增量加載的表、日期分割的表等等。在 Page Not Found | dbt Developer Hub 中查看所有支持的具體化類型。數據完整性測試可以很容易地添加到 YAML 文件中,只需一行。關系完整性、非空值、獨特的主鍵和接受的值都可以在模型上快速檢查。Dbt 理解所有模型的原生依賴性。
Footprint
Footprint 則完成遵循金銀銅結構中描述的方法。按數據的級別分組的做法如下:
2ab5caf-Screenshot_2022-10-27_at_08.35.37.png
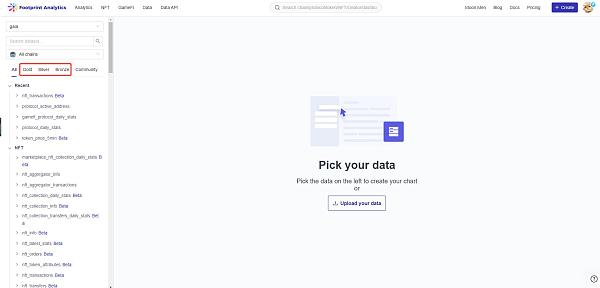
銅數據是未經修改,未經處理的原始數據。 提供所有區塊鏈活動的徹底記錄。交易、日志、痕跡和其他數據,如 EVM 網絡的情況,將以與區塊鏈上的數據相同的方式存儲在這裏。雖然使用這些數據進行查詢是可行的,但要有效地做到這一點,需要對智能合約的內部運作有扎實的掌握。與其他表格相比,這種類型的表格中的數據是最多的。因此,查詢的處理意味着該數據的匯總將需要相當長的時間。
銀數據是未經處理的青銅數據被轉化爲具有附加值的數據集。這可能需要將代碼改爲相關的值,增加合理性檢查,消除不必要的數據,等等。這些表格旨在統一 EVM 和非 EVM 的數據標准,抽象出各領域的數據結構,並建立一個事實上的商業邏輯標准。NFT交易、以太坊代幣轉移、協議交易、合約信息等就是這樣的幾個表。這些表的主要優點是,在EVM和非EVM鏈之間,以及在不同的市場和協議之間切換很簡單。這是因爲數據在語義上被正確組織,使得沒有任何原始區塊鏈數據結構知識的人可以立即使用這些表。
金表是業務層面的數據聚合,直接解決某個領域的問題。在查詢本身中不需要任何聚合(連接和合並,解碼等),金表提供了一些統計指標,可以隨時進行研究。指標可以按原樣使用,節省了开發團隊在开發、運行時計算以及數據驗證和測試方面的時間,因爲像活躍用戶,新增用戶和錢包地址的持有余額這樣的統計數據的所有必要計算已經由 Footprint 完成。
查詢引擎
Dune
DuneV2 改變了整個數據庫架構。Dune 現在正從 PostgreSQL 數據庫過渡到托管在[[Databricks]] 上的 [[Apache Spark]] 的 Instance。
Footprint
Footprint Analytics在 [[Apache Iceberg]] 和 [[Trino]] 數據架構上工作。[[Apache Iceberg]] 是一種用於海量分析數據集的开放式表格格式。[[Trino]]是一個分布式 SQL 查詢引擎,旨在查詢分布在一個或多個不同結構數據源的大型數據集。
執行查詢
Dune
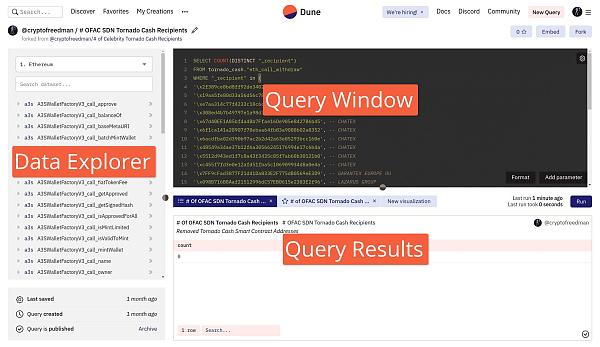
Dune 上所有的查詢都需要通過 SQL 執行。
query-editor.png
Footprint
Footprint 是建立在 [[Metabase]] 之上的。該技術代碼的开放性允許不同的用戶對代碼庫做出貢獻,從而开發和改進它,隨後可以被其他用戶使用。該技術本身實現了一個方便的拖放查詢生成器。這大大降低了進入門檻,允許任何沒有任何技術知識的用戶使用該產品並提取商業價值。
值得注意的是,從架構上來說,Metabase 是對 SQL 代碼的抽象,也就是說,任何通過拖放的請求都可以表示爲 SQL 。因此,想要建立更復雜的查詢的用戶,或者喜歡用代碼處理數據的用戶,都可以在 Footprint 上直接使用 SQL。
可視化
可參考分析師 @escapist5563 在文章《5分鐘快速對比頭部鏈上數據分析平台》的介紹。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:深度對比 Footprint 和 Dune 數據模型
地址:https://www.torrentbusiness.com/article/21157.html
標籤:
你可能感興趣

鐵腕SEC主席Gary Gensler 終在特朗普就任時卸職
2024/11/22 18:22
時代周刊:馬斯克如何一步步成爲“造王”者?
2024/11/22 14:53
幣安CEO寄語:帶領幣安進入加密貨幣新時代的一年
2024/11/22 14:13
低利率低通脹 特朗普變身埃蘇丹?
2024/11/22 14:07
金融巨頭策略轉變?嘉信理財進軍Crypto市場
2024/11/22 13:59