來源:量子號
Ars Technica 今天的一篇頭條文章探討了關於大型語言模型是否具有非語言推理能力的問題,並引用研究人員的發現,稱在“潛在空間”中進行處理可以幫助人工智能解決棘手的邏輯問題。怎么回事呢,我們繼續往下看。
迄今爲止,大型語言模型已經取得了巨大的成功,它們使用其轉換器架構有效地預測響應查詢所需的下一個單詞(即語言標記)。然而,當涉及到需要抽象邏輯的復雜推理任務時,一些研究人員發現,通過這種“語言空間”解釋一切可能會導致一些問題,即使對於現代“推理”模型來說也是如此。
現在,研究人員正試圖通過設計模型來解決這些問題,這些模型可以完全在“潛在空間”——即轉換器生成語言之前的隱藏計算層——中計算出潛在的邏輯解決方案。雖然這種方法不會導致大型語言模型的推理能力發生翻天覆地的變化,但它確實明顯提高了某些類型邏輯問題的准確性,並爲新的研究指明了一些有趣的方向。
等一下,什么空間?
現代推理模型(例如 ChatGPT 的 o1)傾向於通過生成“思維鏈”來工作。在這些模型中,邏輯過程的每個步驟都表示爲一系列自然語言詞標記,並通過模型反饋回來。
在一篇新論文中,Meta 基礎人工智能研究團隊和加州大學聖地亞哥分校的研究人員將這種對自然語言和“單詞標記”的依賴視爲這些推理模型的“基本制約因素”。這是因爲成功完成推理任務,往往需要對特定的關鍵標記進行復雜的規劃,才能從衆多選項中找出正確的邏輯路徑。
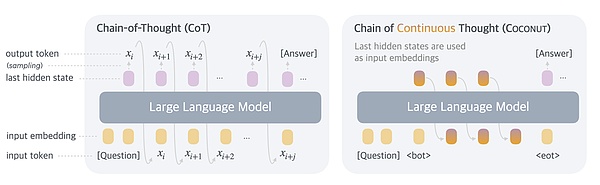
上圖中說明了標准模型每一步都要經過轉換器,與 COCONUT 模型使用隱藏的“潛在”狀態之間的區別。(圖源:Training Large Language Models to Reason in a Continuous Latent Space)
研究人員寫道,在目前的思維鏈模型中,單詞標記通常是爲了“文本連貫性”和“流暢性”而生成的,而“對實際推理過程貢獻甚微”。相反,他們建議,“理想的情況是,大型語言模型可以不受任何語言限制地自由推理,然後只在必要時將他們的發現轉化爲語言。”
爲了實現這一“理想”,研究人員描述了一種“訓練大型語言模型在連續潛在空間中進行推理”的方法,正如論文標題所述。該“潛在空間”本質上是由一組“隱藏”的中間標記權重集組成的,而這些中間標記權重集正是模型在轉換器生成該內部狀態的人類可讀的自然語言版本之前所包含的。
在研究人員的 COCONUT 模型(連續思維鏈)中,這些隱藏狀態被編碼爲“潛在思維”,在訓練和處理查詢時,它們會以邏輯順序取代單個書面步驟。研究人員寫道,這就避免了每一步都要轉換成自然語言,並且“將推理從語言空間中解放出來”,從而產生了一條優化的推理路徑,他們稱之爲“連續思維”。
視野更开闊
雖然在潛在空間中進行邏輯處理對提高模型效率有一定的好處,但更重要的發現是,這種模型可以“同時編碼多個潛在的後續步驟”。在“潛在空間”中進行邏輯處理,可以實現一種即時回溯,研究人員將其比作在圖中進行廣度優先搜索。而不是在一種“貪婪”的過程中,完全地、逐一地尋找各個邏輯選項。
研究人員寫道,即使模型沒有經過明確的訓練,這種突發的、同步的處理特性也會在測試中得到體現。“雖然模型最初可能不會做出正確的決定,但它可以在一些隱含價值函數的引導下,在連續思維中保持許多可能的選擇,並通過推理逐步消除不正確的路徑,”他們寫道。
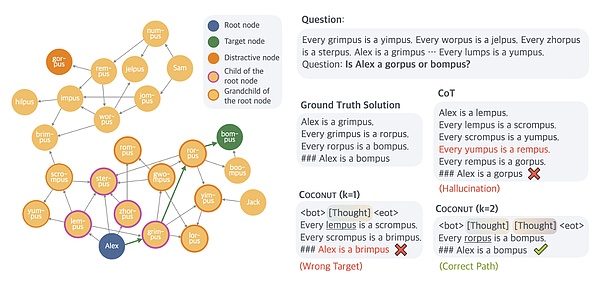
這張圖重點展示了不同模型在某些類型的邏輯推理中可能失敗的一些方式。(圖源:Training Large Language Models to Reason in a Continuous Latent Space)
在相對簡單的數學推理測試 ( GSM8K ) 或一般推理 ( ProntoQA ) 測試中,與傳統的思維鏈模型相比,這種多路徑推理並沒有真正提高 COCONUT 的准確性。但研究人員發現,該模型在一組隨機生成的 ProntoQA 式查詢中表現相對較好,這些查詢涉及復雜而曲折的邏輯條件集(例如,“每個蘋果都是水果,每個水果都是食物,等等”)。
對於這些任務,標准的思維鏈推理模型在嘗試解決邏輯鏈問題時,往往會陷入推理的死胡同,甚至產生完全虛構的規則。先前的研究還表明,這些思維鏈模型輸出的“口頭化”邏輯步驟“實際上可能利用了與共享推理過程不同的潛在推理過程”。
這項新研究加入了越來越多的研究行列,旨在了解和利用大型語言模型在其底層神經網絡層面的工作方式。雖然這類研究尚未取得重大突破,但研究人員認爲,從一开始就用這種“連續思維”進行預訓練的模型,可以“使模型能夠在更廣泛的推理場景中更有效地泛化”。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:大語言模型有非語言推理能力嗎?
地址:https://www.torrentbusiness.com/article/139046.html
標籤:
你可能感興趣

Bitfinex:2025 年中期 比特幣可能會達到 20 萬美元
2024/12/18 14:56
AI vs Crypto:哲學家會選哪一個?
2024/12/18 14:21
艾默生調查:年輕的美國選民如何看待加密、TikTok禁令
2024/12/18 13:50
全球宏觀經濟趨勢將如何影響2025年的加密貨幣市場?
2024/12/18 13:18
11個月突破363億美元 貝萊德IBIT成十年來資金流入最多的ETF?
2024/12/18 12:37